Previous meetings:
2018 Annual Meeting
2019 Annual Meeting
2020 Annual Meeting
2021 Annual Meeting
2022 Annual Meeting
2023 Annual Meeting

10th Annual Unified Communication Framework Workshop and Consortium Meeting (UCF 2024)
Date: December 3-5, 2024
Hybrid Event (In-Person and Virtual via Zoom)
Location: AMD, 7171 Southwest Parkway, Building 100, Austin, Texas
We are delighted to invite researchers, network technology implementers, and users to participate in the 10th Annual Unified Communication Framework (UCF) Workshop and Consortium Meeting 2024. The aim of this gathering is to facilitate the exchange of innovative ideas, state-of-the-art developments, and user experiences, while providing an event to have a dialogue within our growing community. Registration information can be found here.
UCF Annual Meeting and Workshop 2024 Agenda |
||
3-Dec |
||
Start Time |
Session Title |
Presenter |
|
09:00-09:15 |
Opening Remarks and UCF |
Gilad Shainer (NVIDIA) |
|
09:15-10:00 |
UCX in the AMD Instinct MI300 Series Accelerators Eco-System |
Edgar Gabriel (AMD) |
|
10:00-11:00 |
UCX Network Plugin for NCCL |
Thomas Vegas (NVIDIA) |
|
11:00-11:30 |
Lunch |
|
|
11:30-12:15 |
UCX Protocols for Multi-GPU Communication Across NVLink Network |
Ashkay Venkatesh, Mikhail Brinskii, Yossi Itigin, Ilia Yastrebov (NVIDIA) |
|
12:15-13:00 |
EFA Support on UCX |
Thomas Vegas (NVIDIA) |
|
13:00-13:45 |
Hybrid DCS – New DCI Allocation Policy |
Roie Danino (NVIDIA) |
4-Dec |
||
Start Time |
Session Title |
Presenter |
|
09:00-09:15 |
Day 2 Open and Recap |
Pavel Shamis (Pasha) (NVIDIA) |
|
09:15-10:00 |
Optimizing MPI Shared Memory Communication for Modern Multi-core Systems |
Yanfei Guo, Ken Raddenetti, Hui Zhou, Rajeev Thakur (ANL) |
|
10:00-11:00 |
Cross-GVMI UMR Memory Key Pool Optimization |
Ilia Yastrebov, Yong Qin (NVIDIA) |
|
11:00-11:30 |
Lunch |
|
|
11:30-12:15 |
Enhanced Stream API |
Artmey Kovalyov (NVIDIA) |
|
12:15-13:00 |
Addressing Aggregate Efficiency and Offload of RMA Operations at Scale |
Aaron Welch (ORNL), Oscar Hernandez (ORNL) Steve Poole (LANL), Wendy Poole (LANL), Shubhendra Singhal (GT), Akihiro Hayashi (GT) |
|
13:00-13:45 |
Global Virtual Address |
Artmey Kovalyov (NVIDIA) |
Deadlines
-
Abstract submission for a talk and paper due date: October 2, 2024
-
Author notification for abstract acceptance for talk: October 13, 2024
-
Slides for presentations: December 1, 2024
-
Conference presentation: December 3-6, 2024
Information for Technical Talks
Technical Talks require a 250-word abstract and the duration of the presentation can be 30mins or 60mins total (including Q&A). The final presentation slides are required to be provided to the organizers at the event.
Program Committee Members
-
Yong Chen (Texas Tech)
-
John Liedel (Tactical labs)
-
Steve Poole (LANL)
-
Matthew Baker (Voltron Data)
-
Oscar Hernandez (ORNL)
-
Manjunath Gorentla (NVIDIA)
-
Christopher Zimmer (ORNL)
-
Jacques Pienaar (Google)
-
Tony Pena (Barcelona Supercomputing Center)
-
Edgar Gabriel (AMD)
-
Pavel Shamis (NVIDIA)
-
Christopher Taylor (Tactical Computing Lab)
-
DK Panda (Ohio State University)
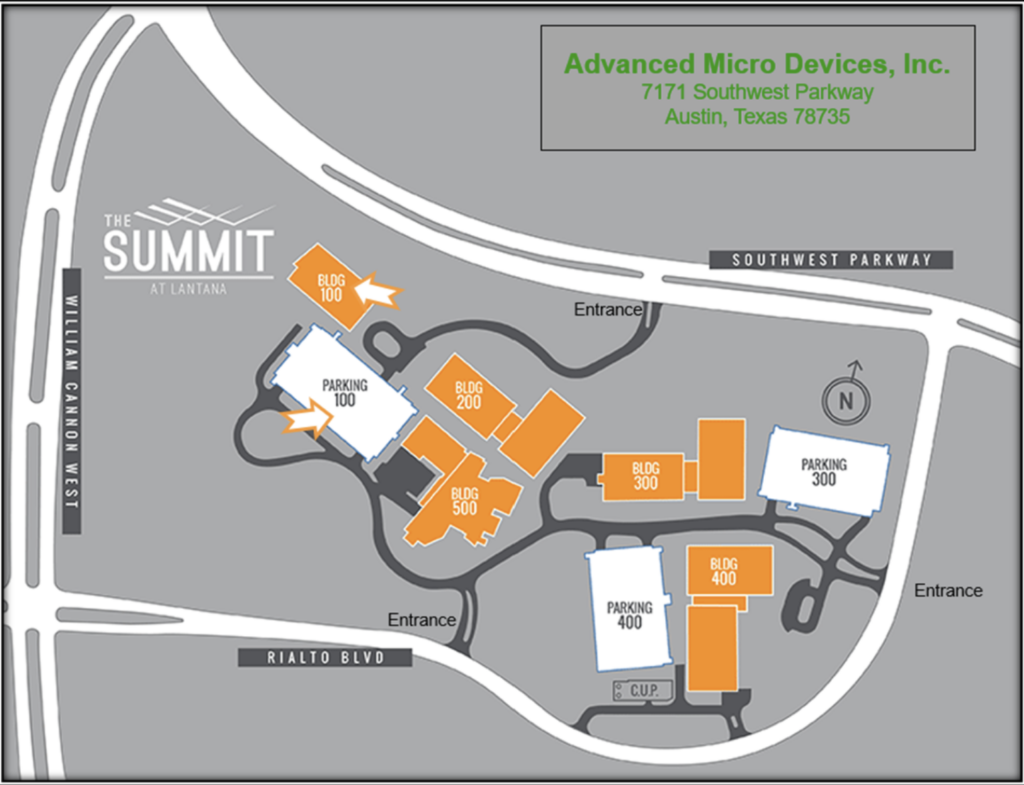
Conference Location
AMD, 7171 Southwest Parkway, Building 100, Austin, TX 78735
Directions:
-
Make sure you turn in at 7171 as other driveways will not connect to the correct building.
-
When you pull onto the campus and follow the curve of the driveway, there will be a building on your right side with circular driveway and three large flagpoles. This is Building 100.
-
Guest parking is available on all levels of the parking structure straight ahead as you pass Building 100.
-
Conference room is located in Building 500.
Hotel and Food Recommendations
-
AC Hotel Austin Hill Country– located across the street from the AMD Campus
-
Sonesta Bee Caves is located in the Hill Country Galleria which is a 10-15 minute drive from the AMD Campus
-
Hill Country Galleria offers lots of dining and shopping
-
Shops at the Galleria located directly across the street from the Hill Country Galleria also has shopping